官方网址:kafka.apache.org
Mirror of Apache Kafka github: https://github.com/apache/kafka
什么是Kafka
Apache Kafka 是一款开源的消息引擎系统, 也是一个分布式流处理平台(Distributed Streaming Platform)
- 处理实时数据提供一个统一、高吞吐、低延迟的平台。
- 它使用的是纯二进制的字节序列, 以时间复杂度为 O(1) 的方式提供消息持久化能力,即使对 TB 级以上数据也能保证常数时间复杂度的访问性能。
- 高吞吐率。即使在非常廉价的商用机器上也能做到单机支持每秒 100K 条以上消息的传输。
- 支持 Kafka Server 间的消息分区,及分布式消费,同时保证每个 Partition 内的消息顺序传输。
- 同时支持离线数据处理和实时数据处理。
- Scale out:支持在线水平扩展。
Kafka功能
削峰填谷解耦合
KafKa传输模型
Kfaka有两种传输模型,分别是基于一对一、多对多的思想。
一对一:一般也称之为消息队列模型,系统 A 发送的消息只能被系统 B 接收,其他任何系统都不能读取 A 发送的消息。
多对多:一般称之为发布订阅模型。与上面不同的是,它有一个主题(Topic)
的概念,该模型也有发送方和接收方,只不过提法不同。发送方也称为发布者(Publisher)接收方称为订阅者(Subscriber)。和点对点模型不同的是,这个模型可能存在多个发布者向相同的主题发送消息,而订阅者也可能存在多个,它们都能接收到
相同主题的消息。
Kafka术语
message
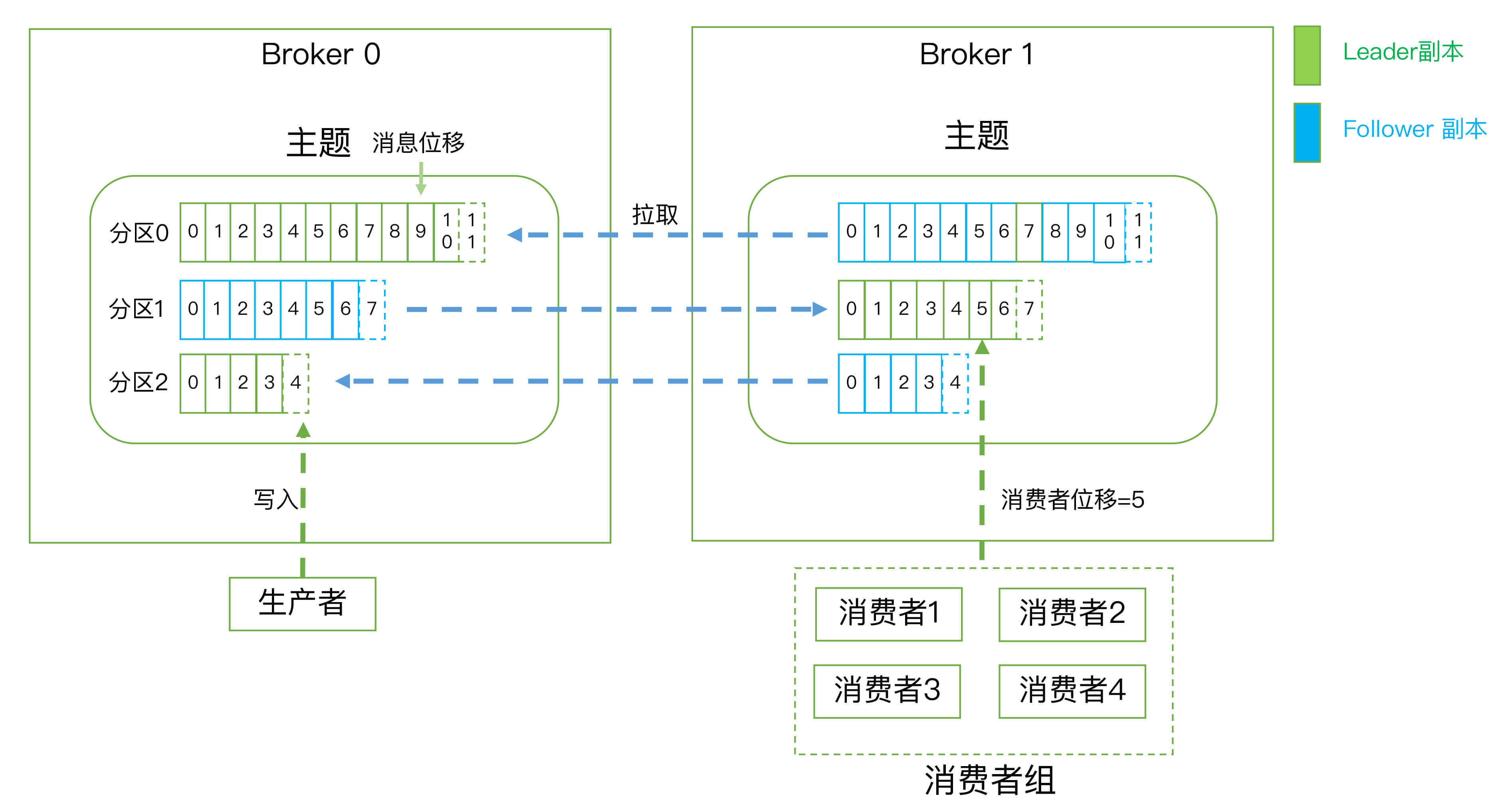
主题(Topic):在 Kafka 中,发布订阅的对象是主题(Topic),你可以为每个业务、每个应用甚至是每类数据都创建专属的主题。
分区(Partitioning):将每个主题划分成多个分区(Partition),每个分区是一组有序的消息日志。生产者生产的每条消息只会被发送到一个分区中
消息(Record):Kafka 是消息引擎,这里的消息就是指 Kafka 处理的主要对象。
客户端
生产者(Producer)
向主题发布消息的客户端应用程序,生产者程序通常持续不断地向一个或多个主题发送消息。
消费者(Consumer)
订阅这些主题消息的客户端应用程序。和生产者类似,消费者也能够同时订阅多个主题的消息。
消费者组(Consumer Group)
多个消费者实例共同组成的一个组,同时消费多个分区以实现高吞吐。
消费者实例(Consumer Instance)
运行消费者应用的进程,也可以是一个线程。
服务端
Broker
Kafka 的服务器端由被称为 Broker 的服务进程构成,即一个 Kafka 集群由多个 Broker 组成,Broker 负责接收和处理客户端发送过来的请求,以及对消息进行持久化。虽然多个 Broker
进程能够运行在同一台机器上,但更常见的做法是将不同的 Broker 分散运行在不同的机器上,这样如果集群中某一台机器宕机,即使在它上面运行的所有 Broker 进程都挂掉了,其他机器上的 Broker 也依然能够对外提供服务。
Replication
把相同的数据拷贝到多台机器上,而这些相同的数据拷贝在 Kafka 中被称为副本(Replica)
副本的数量是可以配置的,这些副本保存着相同的数据,但却有不同的角色和作用。
Kafka 定义了两类副本:
- 领导者副本(Leader Replica):对外提供服务,这里的对外指的是与客户端程序进行交互;
- 追随者副本(Follower Replica):被动地追随领导者副本,不能与外界进行交互。
重平衡(Rebalance)
消费者组内某个消费者实例挂掉后,其他消费者实例自动重新分配订阅主题分区的过程。Rebalance 是 Kafka 消费者端实现高可用的重要手段。
消费者位移(Consumer Offset)
表征消费者消费进度,每个消费者都有自己的消费者位移。

为什么需要使用消息系统
解耦: 消息系统在处理过程中插入了一个隐含的,基于数据接口, 两边的处理过程都要实现这一接口.这允许独立拓展或修改两边的处理过程. 只要确保他们遵循同样的接口约束
而基于消息发布订阅的机制, 可以联动多个业务下流子系统,能够不侵入的情况下的情况下分布编排和开发,来保证数据一致性
冗余:
有些情况下,处理数据的过程中会失败.除非数据被持久化,否则将造成丢失.消息队列吧数据进行持久化直到已经完全被处理, 通过这一方式可规避数据丢失,许多消息队列所采用的”插入-获取-删除”
的范式,把一个消息从队列中删除之前,需要处理系统明确指出该消息已经被完全处理完毕, 从而确保你的数据被安全的保存直到使用完毕
拓展:
消息解耦了处理过程, 所以增大消息入队和处理的频率是简单的,只需要在对应的端加速处理即可. 无需修改代码,修改参数,扩展非常简单
灵活 & 峰值处理能力
在访问量剧增的情况下, 应用仍然需要继续发挥作用,但这样的突发流量并不常见; 如果对此特定时间为标准投入资源,无疑是巨大的浪费. 使用消息队列能使关键组件顶住突发的压力,而不是因为突发的超负荷的请求完全崩溃
可恢复性
系统的一部分组件失效时,不会影响到整个系统. 消息队列降低了进程间的耦合度, 即使一个处理消息的进程挂掉,加入队列中的消息仍然可以在恢复后被处理
顺序
在大多使用厂家下,数据处理的顺序都很重要. 大部分消息队列本来就是排序的,并且能保证数据按照特定的顺序来处理. kafka保证一个Partition内的消息有序性
缓冲
在任何重要的系统中,都会有需要不同的处理时间因素, 消息队列通过一个缓冲层来帮助业务最高效的执行-写入队列的处理尽可能的快速. 缓冲有助于控制和优化数据流和系统的速度
异步通讯
很多时候并不需要立即处理消息,而消息队列提供了异步处理机制, 允许将消息放入到队列,但不立即处理它. 只需要到一定的时间点处理即可