Sekiro简介
开抄!以下来自sekiro官方文档 https://sekiro.virjar.com/sekiro-doc/index.html
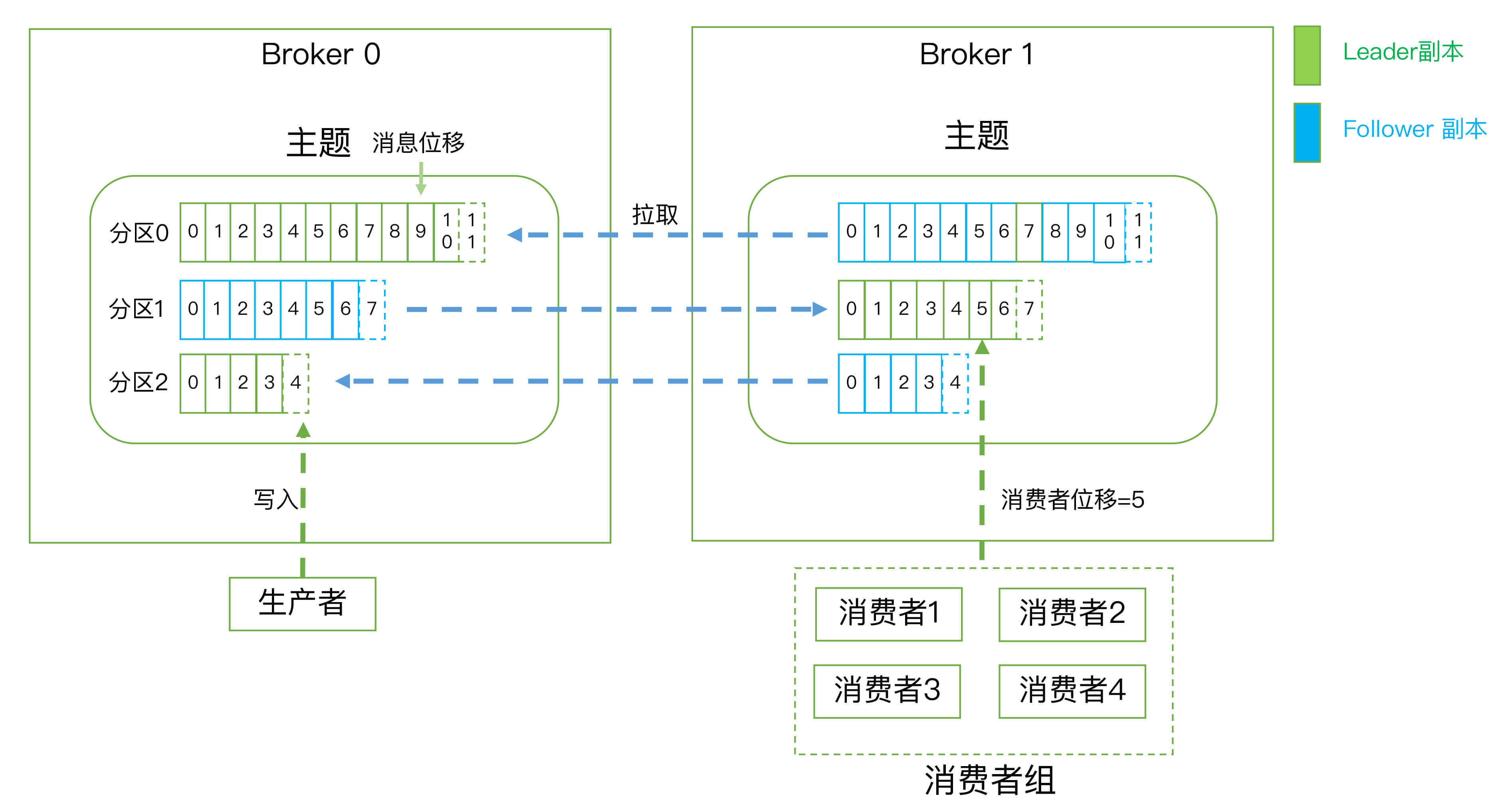
SEKIRO 是一个android下的API服务暴露框架,可以用在app逆向、app数据抓取、android群控等场景。同时Sekiro也是目前公开方案唯一稳定的JSRPC框架。
- 对网络环境要求低,sekiro 使用长链接管理服务(可以理解为每个APP内置内网穿透功能),使得 Android 手机可以分布于全国各地,甚至全球各地。手机掺合在普通用户群体,方便实现反抓突破,更加适合获取下沉数据。
- 不依赖 hook 框架,就曾经的 Hermes 系统来说,和 xposed 框架深度集成,在当今 hook 框架遍地开花的环境下,框架无法方便迁移。所以在 Sekiro 的设计中,只提供了 RPC 功能了。
- 纯异步调用,在 Hermes 和其他曾经出现过的框架中,基本都是同步调用。虽然说签名计算可以达到上百 QPS,但是如果用来做业务方法调用的话,由于调用过程穿透到目标 app 的服务器,会有大量请求占用线程。系统吞吐存在上线(
hermes 系统达到 2000QPS 的时候,基本无法横向扩容和性能优化了)。但是 Sekiro 全程使用 NIO,理论上其吞吐可以把资源占满。 - client 实时状态,在 Hermes 系统我使用 http 进行调用转发,通过手机上报心跳感知手机存活状态。心跳时间至少 20s,这导致服务器调度层面对手机在线状态感知不及时,请求过大的时候大量转发调用由于 client 掉线
timeout。在 Sekiro 长链接管理下,手机掉线可以实时感知。不再出现由于框架层面机制导致 timeout
5.
群控能力,一台Sekiro服务器可以轻松管理上万个手机节点或者浏览器节点,且保证他们的RPC调用没有资源干扰。你不需要关心这些节点的物理网络拓扑结构。不需要管理这些手机什么时候上线和下线。如果你是用naohttpd方案,你可能需要为手机提供一个内网环境,然后配置一套内网穿透。一个内网一个机房,你需要管理哪些机房有哪些手机。当你的手机达到一百台之后,对应的物理网络环境就将会比较复杂,且需要开发一个独立系统管理了。如果你使用的时FridaRPC方案,你可能还需要为每几个手机配置一台电脑。然后电脑再配置内网穿透,这让大批量机器管理的拓扑结构更加复杂。这也会导致手机天然集中在一个机房,存在IP、基站、Wi-Fi、定位等环境本身对抗。 - 多语言扩展能力。Sekiro的客户端lib库,目前已知存在Android(java)、IOS(objective-c)、js(浏览器)
、易语言等多种客户端(不是所有的都是Sekiro官方实现)。Sekiro本身提供一个二进制协议(非常简单的二进制协议规则),只要你的语言支持socket(应该所有语言都支持)
,那么你就可以轻松为Sekiro实现对应客户端。接入Sekiro,享受Sekiro本身统一机群管理的好处。在Sekiro的roadmap中,我们会基于frida
Socket实现frida的客户端,完成Frida分析阶段的代码平滑迁移到Sekiro的生产环境。尽请期待
7.
客户端接入异步友好。Sekiro全程异步IO设计,这一方面保证整个框架的性能,另一方面更加贴近一般的app或者浏览器本身的异步环境。如果rpc调用用在签名计算上面,大部分签名仅仅是一个算法或者一个so的函数调用。那么同步调用就可以达到非常高的并发。但是如果你想通过rpc调用业务的API(如直接根据参数调用最网络框架的上层API,把参数编解码、加解密都,逻辑拼装都看作黑盒)。此时普通同步调用将会非常麻烦和非常消耗客户端性能。异步转同步的lock信号量机制、同步线程等待导致的线程资源占用和处理任务挤压等风险。FridaRPC支持异步,但是由于他的跨语言问题,并不好去构造异步的callback。目前nanohttpd或者FridaPRC,均大部分情况用在简单的签名函数计算上面。而Sekiro大部分用在上游业务逻辑的直接RPC场景上。 - API友好(仅对AndroidAPI),我们为了编程方面和代码优雅,封装了一套开箱即用的API,基于SekiroAPI开发需求将会是非常快乐的。
简而言之呢,Sekiro是一个virjar开发的一款强大稳定的rpc服务暴露框架
Kubernetes上部署
首先,我们需要有一个 Kubernetes 集群,可以自己搭建,也可以使用 Minikube 或者用阿里云、腾讯云、Azure 等服务商直接提供的 Kubernetes 服务。 另外我们需要能使用 kubectl 连接和控制当前的集群,
- 搭建 Kubernetes 集群:https://kubernetes.io/docs/setup/production-environment/tools/kubeadm/create-cluster-kubeadm/
-
Minikube:https://kubernetes.io/docs/tutorials/hello-minikube/
-
基于Kubeadmin实现Kubernetes 集群搭建: https://paynewu.com/18864.html
上面的内容准备就绪之后,就可以开始 Kubernetes 搭建。搭建完成之后就开始部署Sekiro吧
在Kubernetes中容器环境部署那就离不开image,Sekiro的image为
1 |
registry.cn-beijing.aliyuncs.com/virjar/sekiro-server:latest |
无论是Docker、还是podman、亦或者是其他的容器。现成的景象就用这个
Kubernetes部署服务的常用的有三种形式
- kubectl cli部署
- 基于YAML文件格式部署
- 基于JSON文件格式部署
部署服务
首先为此创建一个名为crawleruntil 的 namespace
1 |
kubectl create namespace crawleruntil |

因为我已经有
crawleruntil这个namespace以及其他的服务,为了方便就不删了在演示了,将图中的sekiro即可
至此已经完成四分之一了,接下来进行Sekiro的部署,yaml文件如下
1 |
apiVersion: apps/v1 |
将其复制到服务器上,然后使用命令kubectl apply -f 此文件名,当然kubectl create -f 此文件名也可以大差不差。
稍等几秒甚至是一两分钟,看看

确认使用kubectl get all -n crawleruntil 中显示的内容中有STATUS均为Running, 代表就部署成功了
当然这还并不足以使服务可用,因为sekiro它运行在容器内的网络,暂时还无法在本地、或者远程反问服务。此时就需要将服务暴露出去。以便于使用
服务暴露
暴露服务有NotePort, LoadBalance, 此外externalIPs也可以使各类service对外提供服务。当然最推荐的还是Ingress, 关于Ingress是什么感兴趣的请自行搜索。
首先先需要部署ingress collector,请搜索。部署完成后可采用如下YAML进行ingress服务暴露
1 |
# https |
此时访问你外网地址, 就会发现。(80需要有权限打开访问哦)

ok,部署完成了! sekiro就可以食用啦。
以上明显还不够,主要是两个问题
没有身份验证: 那么就意味着任何人都可以调用你的这个接口,岂不是…
某些网页端的JS有证书,这样部署的sekiro无法使用此场景,需要为之加上tls证书。
Ingress 网页添加认证
想偷懒的可以直接使用这三条命令。认证令牌创建一步到位
1 |
yum -y install httpd |
我这里默认采用机器的hostname base64后的字符为用户名与密码。
1 |
echo `echo $(hostname) | base64` :密码改这里面的内容 |
然后直接使用kubectl create secret generic basic-auth-secret --from-file auth --namespace=crawleruntil
创建一个名为basic-auth-secret generic类型的secret。
注意需要将namespace 指定为crawleruntil,实现同意命名空间
将它挂到Ingress上去,
Ingress YAML如下
1 |
# https |
打开一个无痕浏览器,此时你就可以发现

这玩意需要认证了,cool~
域名解析与TLS网络证书
域名:首先你得需要有域名,这个去阿里云、腾讯云、华为云还是等等买就是咯。
证书:将你申请点TLS证书下载到本地,具体请搜索
创建证书的secret, 如下
1 |
kubectl create secret tls tls-sekiro-paynewu-com --key sekiro.paynewu.com.key --cert=sekiro.paynewu.com_bundle.crt --namespace crawleruntil |
最终的Ingress YAML如下
1 |
|
根路径


注入验证
将 https://sekiro.virjar.com/sekiro-doc/assets/sekiro_web_client.js 中的文件复制到控制台,执行
然后在控制台调用
1 |
var client = new SekiroClient("wss://域名/websocket?group=ws-group-test&clientId=" + guid()); |
校验

完成~
Referer
其他部署都可以看看邱佬的